
What I’m Reading: LLMs Ace Medical Benchmarks, But Users Don’t
A 1,298-person RCT on LLM-assisted medical reasoning landed in Nature Medicine this week, and the gap between benchmark performance and real-world utility is striking.
Models scored between 90–99% on standalone evaluations for identifying relevant conditions. Real-world users with access to the same models hit 34.5%.
This exposes that this is a fundamentally different task.
The middle ground makes the story richer: models mentioned relevant conditions in 65–73% of the conversations—already a step down from benchmark performance—but users then failed to recognize or retain those conditions in their final answers. So the information was often there (though not 90-99% of the time), just not transferred.
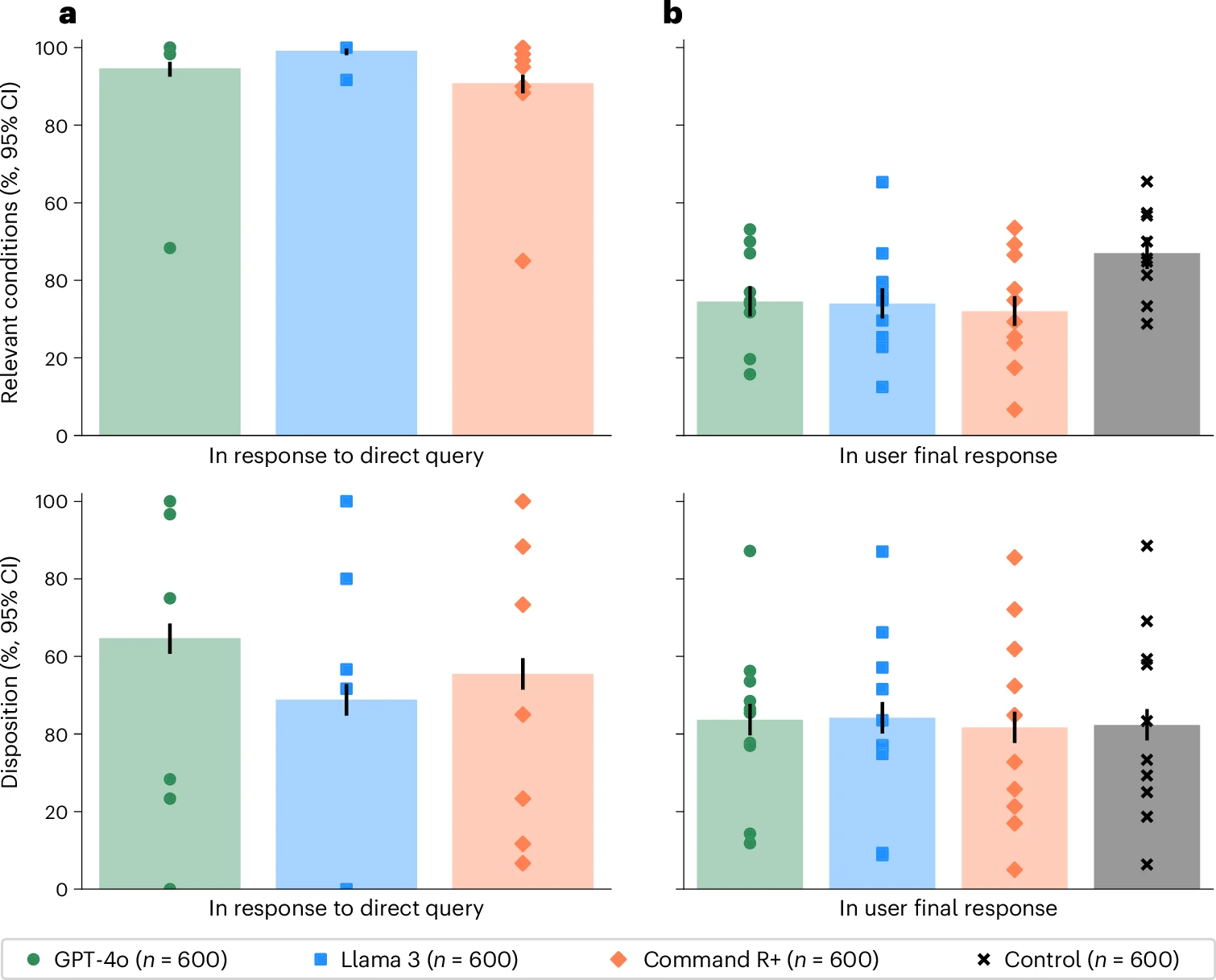
I keep thinking about the methodology. Standalone benchmarks feed models a full clinical vignette and ask for an answer. A back-and-forth dialogue is structurally different—it distributes information across turns, requires active synthesis, and introduces retrieval demands on the human side. We already know LLMs perform better with complete context windows. This paper operationalizes that it matters in practice.
Two questions this raises for me:
Do we need benchmarks that account for the human-in-the-loop performance hit? Frontier capability clearly doesn’t translate automatically to clinical utility, and the gap here is large enough that it should change how we think about deployment readiness.
What does this mean for clinical AI interfaces? If users are missing conditions that models mention, the bottleneck isn’t the model. Is it the interaction design, the information architecture, or what we’re asking users to do with AI-generated output?
Worth reading if you’re thinking about AI in clinical settings.
Comments